※ 이 글은 chatGPT를 기반으로 작성한 글입니다.
Seq2Seq 모델
① Seq2Seq(Sequence-to-sequence) 모델은 주로 자연어 처리 분야에서 사용되는 딥 러닝 아키텍처다.
㉠ 이 모델은 한 시퀀스를 다른 시퀀스로 변환하는 데 사용된다.
② Seq2Seq 모델은 크게 두 부분, 인코더(encoder)와 디코더(decoder)로 구성된다.
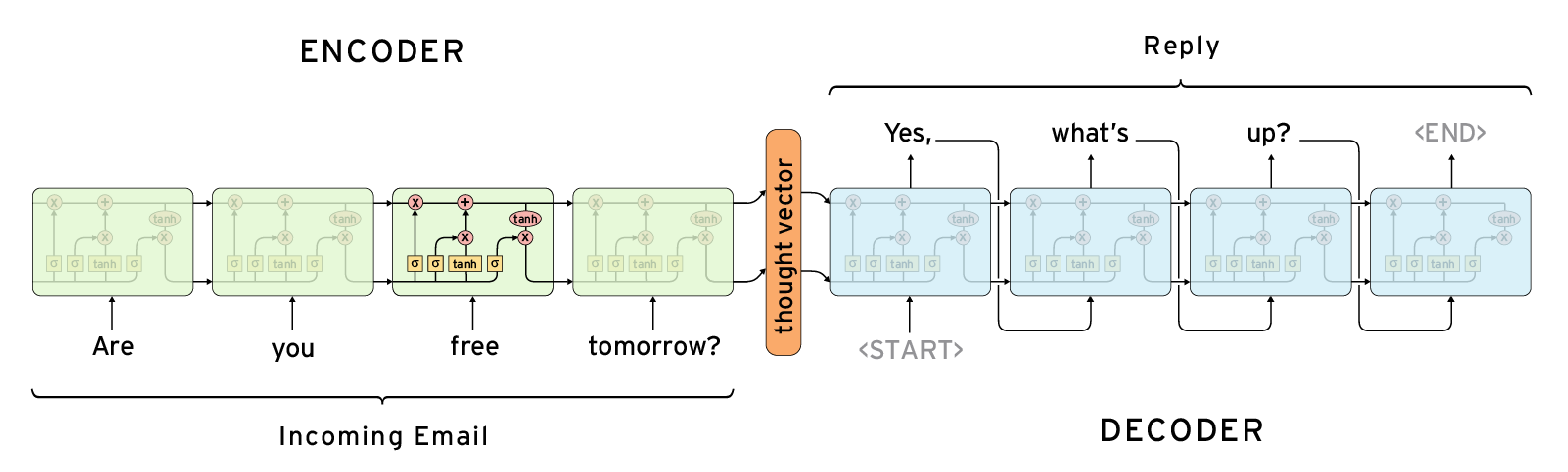
인코더
㉠ 일반적인 인코더의 역할은 입력 시퀀스(문장)의 각 요소(단어)를 벡터들로 변환하는 것이다.
㉡ 입력 데이터를 처리하는 단계는 크게 세 부분으로 나뉘며, ⓐ 토큰화(tokenization), ⓑ 벡터 변환(vectorization), ⓒ 컨텍스트 벡터 생성(context vector generation)으로 구분된다.
ⓐ 토큰화(Tokenization)
• 토큰화는 긴 텍스트 스트링을 더 작은 단위(토큰)로 분리하는 과정이다.
⚬ 보통 단어, 구, 또는 문자로 나뉘며, 기계 번역이나 텍스트 요약과 같은 작업에서는 단어나 구가 토큰으로 사용된다.
⚬ 예를 들어 문장 "Hello, World!"를 토큰화하면 ["Hello", ",", "world", "!"]와 같은 토큰의 리스트로 변환될 수 있다.
⚬ 각 토큰은 데이터의 기본적인 의미 단위를 나타낸다.
• 토큰화를 통해 비구조화된 텍스트 데이터를 구조화된 형태로 변환할 수 있다.
ⓑ 벡터 변환(Vectorization)
• 각 토큰은 일반적으로 벡터로 변환되는데 이 과정은 단어 임베딩(word embedding)이라고 불린다.
⚬ 이 과정은 토큰을 컴퓨터가 이해할 수 있는 수치적 형태로 변환하는 과정이다.
⚬ 각 토큰을 고정된 크기의 벡터로 변환해서 토큰의 의미적, 문법적 특성을 나타낼 수 있다.
• 단어의 의미를 포착할 수 있는 밀집 벡터 형태로 단어를 표현한다.
⚬ 임베딩 기법으로 Word2Vec, GloVe, FastText 등의 기법이 존재한다.
• 임베딩을 통해 고차원의 텍스트 데이터를 저차원의 벡터로 변환하여 계산 효율성을 높일 수 있다.
ⓒ 컨텍스트 벡터 생성(Context vector generation)
• 인코더는 이 임베딩된 벡터들을 처리하여 입력 시퀀스의 전체적인 정보를 담고 있는 컨텍스트 벡터를 생성한다.
• 컨텍스트 벡터는 입력 시퀀스(문장)의 중요한 특성 등을 고정된 길이의 벡터로 압축시켜 표현한 것이다.
⚬ 전통적으로 RNN, LSTM 또는 GRU와 같은 순환 신경망이 컨텍스트 벡터를 생성하는 데 사용된다. 이 신경망은 시퀀스의 각 요소를 처리하여 은닉 상태(hidden state)를 업데이트 한다.
• 디코더는 컨텍스트 벡터를 이용해서 의미있는 출력 시퀀스를 생성해 낸다.
• 전통적인 Seq2Seq 모델에서 컨텍스트 벡터는 긴 입력 시퀀스를 단일 벡터에 압축시키는 과정에서 정보 손실이 발생했고, 이는 어텐션 메커니즘을 도입한 배경이 되었다.
디코더
㉢ 디코더는 인코더에서 생성된 컨텍스트 벡터와 은닉 상태(hidden state)를 사용하여 새로운 출력 시퀀스를 생성한다.
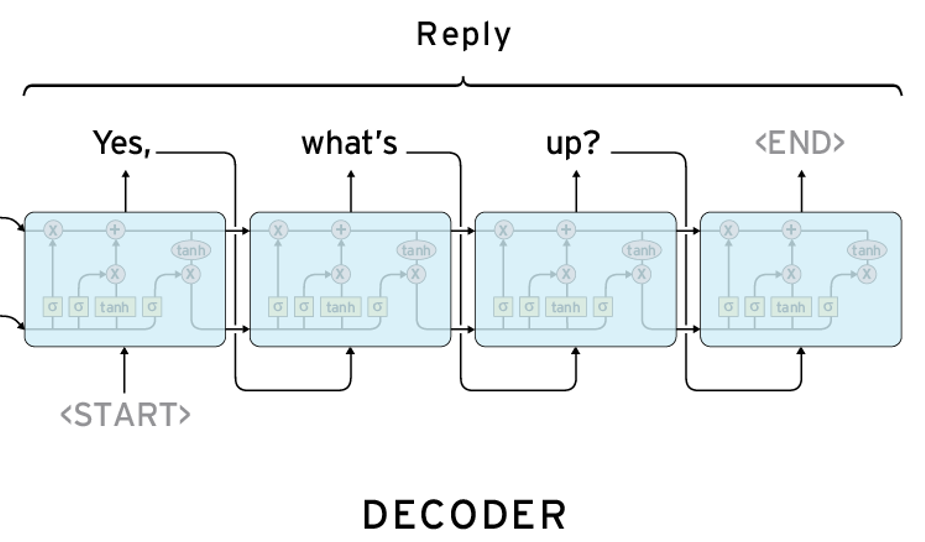
ⓐ 디코더는 이전에 생성된 시퀀스 요소, 컨텍스트 벡터, 입력 시퀀스를 고려하여 재귀적으로 출력 시퀀스의 요소를 한 개씩 예측한다.
ⓑ 첫 번째 디코더의 경우 이전에 생성된 시퀀스 요소가 존재하지 않기 때문에 <START>처럼 특별한 시작 토큰을 입력으로 출력 시퀀스 요소를 생성한다. 이 때 생성된 출력 시퀀스 요소인 yes가 다음 디코더의 입력으로 사용 된다.
ⓒ 디코더는 각 단계에서 출력 시퀀스 요소를 출력하며, <END>와 같이 특별한 종료 토큰이 생성될 때까지 반복한다.
'All about Machine-Learning > NLP' 카테고리의 다른 글
| 트랜스포머 모델 구현 (0) | 2024.01.12 |
|---|---|
| 어텐션 메커니즘과 트랜스포머 모델 (0) | 2024.01.12 |
| 어텐션 메커니즘(Attention Mechanism)의 원리 (0) | 2024.01.12 |
| 워드 벡터(Word Vector) -CBOW, Skip-gram (0) | 2024.01.06 |
| 허깅 페이스(Hugging Face) (2) | 2023.12.21 |