① 순환신경망(Recurrent Neural Network)는 시퀀스 데이터(sequence data)를 처리하기 위해 설계된 신경망이다.
㉠ 시퀀스 데이터는 시간의 흐름에 따라 순서대로 나열된 데이터를 의미한다.
ⓐ 시퀀스 데이터의 예시로는 문장(단어들의 시퀀스), 주식 시장 데이터(시간에 따른 주가 변화), 음성 신호(연속적인 음향 데이터) 등이 있다.
㉡ 순환 신경망은 시퀀스의 각 요소가 이전 요소와 어떻게 연관되어 있는지 학슴함으로써 시퀀스 데이터에 숨겨진 패턴과 관계를 찾을 수 있다.
② 순환신경망은 이전 출력이 입력으로 사용될 수 있도록 하는 구조를 가진 신경망이다.

③ 순환 신경망은 각 시퀀스 요소를 처리하는 셀(cell)이라는 구조를 사용한다.
㉠ 셀은 현재 입력과 이전 셀의 출력(이전 시점의 정보)를 받아 현재 셀의 출력을 생성한다.
㉡ 각 셀의 출력 y(t)는 은닉 상태(hidden state)라고도 하며, 시퀀스의 정보를 시간에 걸쳐 전달하는 역할을 한다.
④ 순환 신경망에서의 셀 내부의 구조는 다음과 같다.
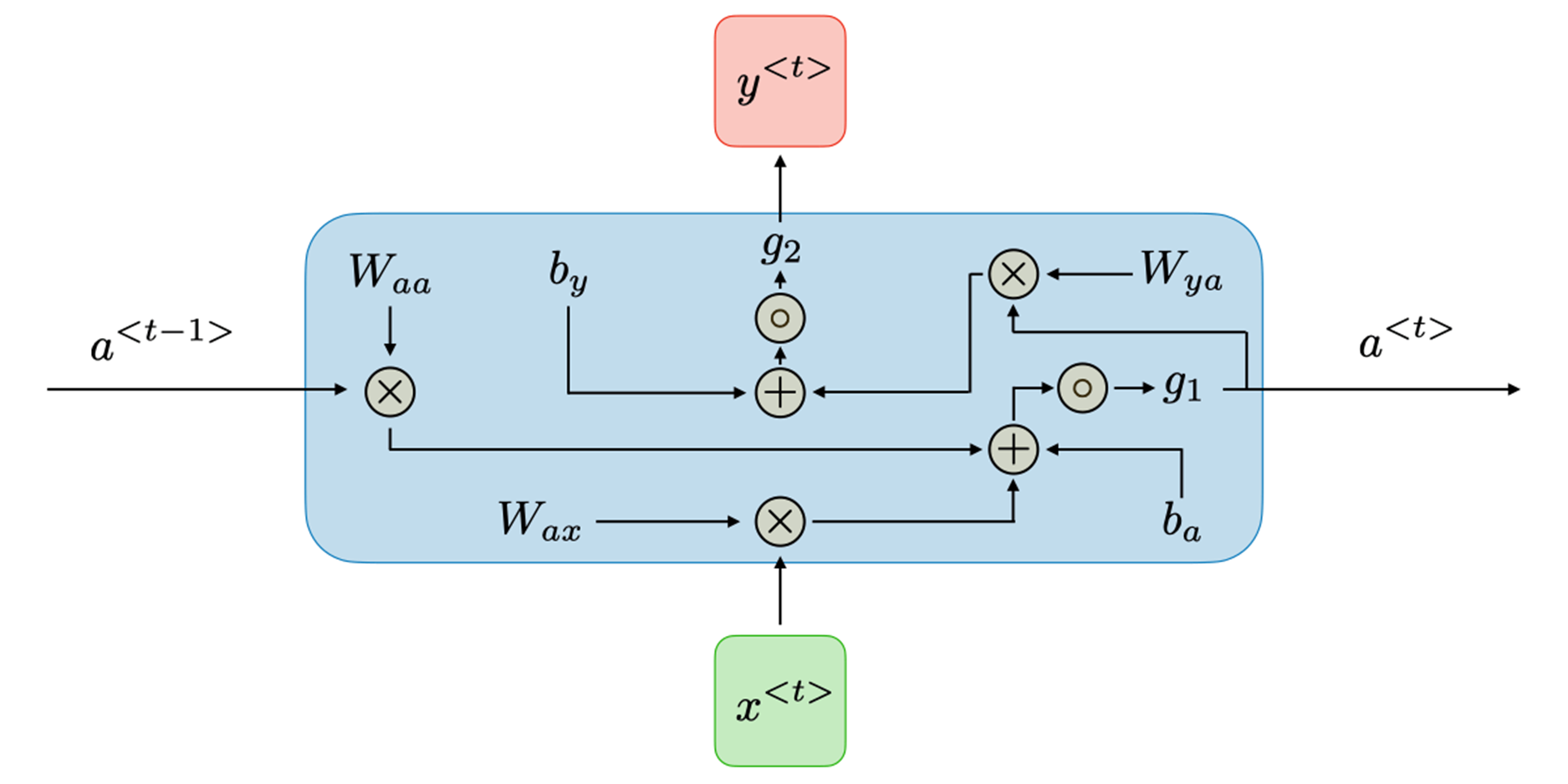
㉠ RNN의 셀 구조는 과거의 정보를 현재의 의사결정과 결합하여 미래의 출력을 예측하는 데 중요한 역할을 한다.
㉡ 순환 신경망의 각 셀에서 이뤄지는 작동 원리는 크게 두 개의 방정식으로 정의할 수 있다.
㉢ 첫 번째 방정식은 각 시간 간격 t에서의 은닉 상태 \( a^{< t >} \)를 계산하는 방정식이다.
\(\boxed{a^{< t >}=g_1(W_{aa}a^{< t-1 >}+W_{ax}x^{< t >}+b_a)}\)
ⓐ 활성화 함수 \( g_1\) 은 전통적으로 기울기 폭발을 방지하기 위해 tanh(Hyperbolic tangent) 함수를 전통적으로 사용한다.
ⓑ \(W_{aa}\)은 이전 은닉 상태 \(a^{< t-1 >}\) 에서 현재 은닉 상태로의 연결에 대한 가중치 행렬이다.
ⓒ \(W_{ax}\)는 현재 입력 \(x^{< t >}\)에서 현재 은닉 상태로의 연결에 대한 대한 가중치 행렬이다.
ⓓ \(b_a\)는 은닉 상태의 편향이다.
ⓔ 결과적으로 이 방정식은 이전 은닉 상태와 현재 입력을 결합하여 새로운 은닉 상태를 생성해 낸다.
㉣ 두 번째 방정식은 각 시간 간격 t에서의 출력값 \( y^{< t > \)을 계산하는 방정식이다.
\(\boxed{y^{< t >}=g_2(W_{ya}a^{< t >}+b_y)}\)
ⓐ 활성화 함수 \( g_2\) 은 \( g_1\)과는 다른 목적을 위해 사용되는 활성화 함수로, 회귀나 분류 문제의 경우 소프트맥스(softmax) 함수가 주로 활성화 함수로 사용하며, 다른 종류의 문제에서는 다른 활성화 함수가 사용될 수 있다.
ⓑ \(W_{ya}\)은 현재 은닉 상태 \(a^{< t >}\) 에서 출력으로의 연결에 대한 가중치 행렬이다.
ⓒ \(b_y\)는 출력의 편향이다.
ⓓ 결과적으로 이 방정식은 시간 간격 t에서의 은닉 상태를 출력값으로 변환하며, RNN의 사용 목적에 따라 예측 또는 분류를 위해 사용할 수 있다.
⑥ 일반적인 RNN 구조의 장점을 요약하면 다음과 같다.
㉠ 시퀀스의 길이에 상관없이 입력을 처리할 수 있다. 이는 텍스트, 음성 등의 시퀀스 데이터를 처리하는 데에 유용하다.
㉡ 입력 시퀀스의 길이와 상관없이 일정한 크기의 모델을 유지한다. 이는 모델이 크고 복잡해지는 것을 방지한다.
㉢ 이전 시점의 정보를 현재의 의사결정에 활용한다. 이를 통해 시퀀스의 시간적인 동적 특성을 파악할 수 있다.
㉣ 시간에 따라 동일한 가중치를 재상요하기 때문에 파라미터의 개수를 줄이고, 학습을 보다 효율적으로 만든다.
⑦ 일반적인 RNN 구조의 단점을 요약하면 다음과 같다.
㉠ 이전 단계의 출력이 다음 단계의 입력으로 사용되기 때문에 연속적인 계산이 필요하며 병렬 처리가 어렵다.
㉡ 기울기 소실(vanishing gradient) 문제로 인해 긴 시퀀스를 학습할 때 학습 과정이 비효율적이거나 불가능해지게 만든다.
ⓐ 따라서 일반적인 RNN 구조는 오래된 정보를 기억하는 데 어려움이 있다.
ⓑ LSTM이나 GRU와 같은 고급 RNN 구조를 통해 해결할 수 있다.
㉢ 기본 RNN 구조는 현재와 과거의 정보만을 고려할 수 있으며, 미래의 입력 정보는 고려하지 않는다. 이를 해결하기 위해 양방향 RNN이 사용될 수 있다.
'All about Machine-Learning > 기본' 카테고리의 다른 글
| BERT(Bidirectional Encoder Representations from Transformers) (0) | 2023.12.21 |
|---|---|
| 손실 함수(Loss function) (0) | 2023.03.05 |
| 모델의 복잡도 (0) | 2023.03.05 |
| 전처리(Preprocessing) (0) | 2023.03.05 |
| 과적합(Overfitting) (0) | 2023.03.05 |